

Unter diesem Motto habe ich im April 2020, den lang ersehnten Release-Wechsel der „4er-Version“ begleiten können und ich muss wirklich sagen, das war ein gefühlter Quantensprung. Der Umstieg von der Flash- auf die HTML-Oberfläche hat vor allem bei den Admins für eine riesen Erleichterung gesorgt.
Schon die Release-Notes lasen sich vielversprechend:
Mehr als 7.500 PT Entwicklungszeit wurden in OMN5 investiert – die bisher größte Einzelinvestition in der Geschichte der apollon. Beste User Experience, modernste, richtungsweisendeTechnologie und maximale Automatisierung dank künstlicher Intelligenz (KI) bilden die drei Grundpfeiler der neuesten Version.
Mittlerweile wurde bereits die Version 6 released, die Basics sind jedoch weitestgehend gleich geblieben und wir wollen jetzt damit beginnen, uns anzuschauen wie sich das System dem Anwender präsentiert.
I - OMN Startseite
Die Startseite des Apollon OMN 5 ist so individuell, wie das System selbst.
Über die Backend-Konfiguration kann diese Seite frei gestaltet werden. Es kann ein einfacher Welcome-Screen sein, der den Benutzer namentlich begrüßt, geschmückt mit dem Company-Logo oder einem Unternehmensclaim, sogar die Einbindung von Videos oder Musik ist problemlos möglich, einfach durch die Einbettung kompletter HTML-Skripte.
Die Praxis zeigt aber, sowas ist am Anfang ganz nett und zeigt, wie kreativ der Admin mit dem System umgehen kann. Fakt ist aber, NIEMAND braucht so etwas. Denn es ist nur ein weiterer unnötiger Klick, bis man mit der Arbeit beginnen kann.
Demnach erscheint es wesentlich sinnvoller, hier ein Element zu platzieren, dass im direkten Zusammenhang mit der Arbeit steht. In Frage kommen hier Bekanntmachungen im Stile eines Intranets, To-Do-Listen mit zugewiesenen Aufgaben, Terminübersichten oder einer Statusübersicht, über angefangene oder noch anstehende Aufgaben, so wie man es kennt nach dem altbekannten Ampelsystem.
Ob nun solche Instrumente benötigt werden, liegt an der Implementierungstiefe des PIM-Systems im Tagesgeschäft. Wenn prozessual keine Aufgaben zugewiesen werden, sprich innerhalb von Teams oder auch abteilungsübergreifend oder Deadlines nicht das Tagesgeschäft bestimmen, dann kann die Startseite auch ein sinnvolles Onboard-Feature beinhalten: Eine globale Suche.
Schauen wir mal rein!
II - Anlage eines Klassifizierungsbaumes
Organisation der Produktdaten ermöglicht wird.
Für den späteren Anwender, der Produktdaten pflegen soll, bietet ein gut gestalteter Klassifizierungsbaum mehrere Vorteile:
Strukturierte Datenorganisation: Durch die klare Hierarchie des Klassifizierungsbaums wird die Organisation von Produktdaten erleichtert, was die Auffindbarkeit und Verwaltung der Daten verbessert.
Konsistente Datenerfassung: Der Klassifizierungsbaum definiert die Attribute, die für jedes Produkt erfasst werden müssen. Dadurch wird sichergestellt, dass Daten konsistent erfasst werden, was die Qualität und Vergleichbarkeit der Produkte verbessert.
Vererbung von Attribute: Ein weiterer wichtiger Aspekt des Klassifizierungsbaums ist die Möglichkeit der Attributvererbung. Auf oberen Ebenen definierte Attribute können automatisch auf untergeordnete Produktebene übertragen werden, was den Pflegeaufwand reduziert und die Datenkonsistenz erhöht.
Benutzerfreundlichkeit: Ein gut strukturierter Klassifizierungsbaum erleichtert es Anwendern, Produkteigenschaften intuitiv zu finden und zu bearbeiten, da sie sich an eine klar definierte Hierarchie halten können.
Insgesamt spielt der Klassifizierungsbaum eine entscheidende Rolle bei der Organisation und Verwaltung von Produktdaten in einem PIM-System, indem er eine strukturierte und benutzerfreundliche Umgebung für die Datenerfassung und -verwaltung bereitstellt.
III - Definition von Artikel-Attributen
Zugegeben, an den Sprachgebrauch musste ich mich erst gewöhnen, denn Attribute waren für mich immer nur Eigenschaften, wie Farben oder Größen. Doch je tiefer man eintaucht in die Welt der Daten, Datenbanken und PIM-Details, um so deutlicher wird, das eigentlich alle eingegebenen Daten in Attributen hinterlegt sind.
Da haben wir ganz banale Felder wie die Artikelnummer, eine GTIN oder den Preis. Aber auch Beschreibungstexte in Lang- oder Kurzform für das Internet, der Katalogtext und auch Asset-Referenzen wie Haupt- und Anwendungsbilder, sind Attribute.
IV - Attribute mit Standard-Values (Standardattribute)
Streng genommen sind es keine Standardattribute, sondern Attribute mit Default belegten Attributwerten.
Die Absicht dahinter liegt ganz offensichtlich auf der Hand. Zeitersparnis!
Warum soll ein Wert, hunderte Male an Artikeln in einer Klassifzierung gepflegt werden, wenn man doch einen Default-Wert
hinterlegen kann.
Ein Praxisbesipiel stellt die Definition der Google-Product-ID da. Dieser Wert ist zum Beispiel für alle Autoreifen gleich. Er hilft
lediglich Google bei seinen Follow-Up Prozessen und es wäre müßig, diesen Wert a) jedes Mal zu recherchieren und b) dann auch noch zu hinterlegen.
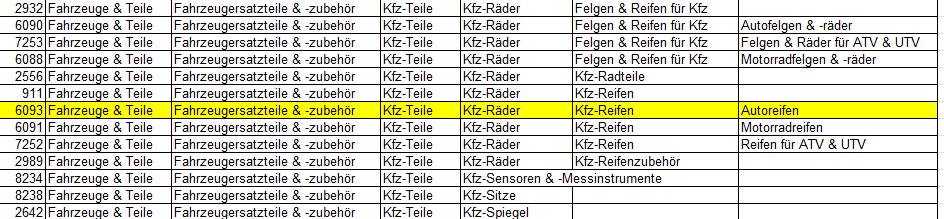 Quelle: taxonomy-with-ids.de-DE.xls
Quelle: taxonomy-with-ids.de-DE.xls
Dieser Wert wird somit einmalig für eine Klassifizierungsebene hinterlegt und für die stadardmäßige Ausleitung in einen bestimmten Zielkanal aktiviert. Dies kann der Webshop sein, aber auch ein gesonderter Google-Shopping-Stream.
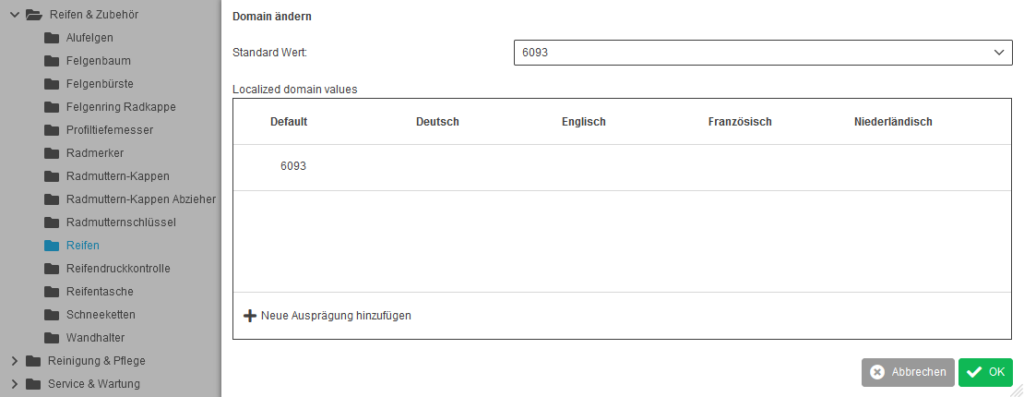
Quelle: Selbst
V - Customized Function - Blacklisting
Über Java-Skripte lassen sich unglaubliche Funktionen erweitern. Diese können, bei entsprechender Kenntnis der Datenbankstruktur und des Datenmodells, auch selbst erstellt und implementiert werden. An dieser Stelle die ausdrückliche Warnung, wenn man das schon selbst machen will, dann bitte vorab auf dem Development-System testen oder von dem Anbieter-Entwickler gegenchecken lassen.
Ich hab jetzt hier mal ein Feature mitgebracht, dass unter dem Namen „Blacklisting“ bekannt ist. Dahinter verbirgt sich eine Prüfung auf Begriffe, die in einer Tabelle erfasst sind und die bei einem Produktbeschreibungstext gar nicht, oder nur unter bestimmten Voraussetzungen verwendet werden dürfen.
Im folgenden Beispiel verwende ich den Begriff „Teflon“, der rechtlich geschützt ist und nur im Zusammenhang mit Produkten einer bestimmten Marke verwendet werden darf.
Seht selbst, wie der Redakteur „kontrolliert“ wird.